Poker Bot Project
Introduction
Many ML models are trained to perform well against optimal or near-optimal behavior, but real-world opponents are inconsistent and unpredictable. This led me to wonder if training for theoretically strong play also leads to the highest payoff against imperfect opponents. In Kuhn Poker, game-theory optimal (GTO) strategies aimed at minimizing exploitation are not guaranteed to yield the highest returns against imperfect opponents.
I modify Deep CFR, a self-play learning method that uses neural networks to approximate action preferences. My project investigates smoothing this learning process to produce strategies that perform better against imperfect opponents. The input to the model is the information state $I$, which consists of the private card and the public betting history. The model outputs a probability distribution over the legal actions $a$ (check, bet, etc.).
TLDR
Related Work
Counterfactual Regret Minimization (CFR) solves two-player zero-sum imperfect-information games by breaking down global regret into counterfactual regrets. Deep CFR uses neural networks to approximate these regrets from sampled traversals. I test whether a moderate smoothing of regret matching inside Deep CFR changes performance by evaluating cross-play EV against MCCFR opponents of varying strength.
Dataset and Features
Training data comes from self-play in OpenSpiel’s Kuhn Poker environment. Each sample corresponds to an information state $I$ and the regret or strategy targets produced by the Deep CFR solver. Evaluation is determined by post-training cross-play.
Methods
Problem setting
At each decision point, a player observes an information state $I$, and must choose an action $a \in A(I)$. A policy $\sigma(I)$ is a probability distribution over the legal actions.
Counterfactual regret minimization
Let $R_t(I,a)$ denote the cumulative counterfactual regret for action $a$ at information state $I$ after iteration $t$, and let $R_t^+(I,a) = \max{R_t(I,a), 0}$.
Standard regret matching defines the next policy by:
$$ \sigma_{t+1}(a|I) = \frac{R_t^+(I,a)}{\sum_{a’ \in A(I)} R_t^+(I,a’)} \quad \text{if } \sum_{a’ \in A(I)} R_t^+(I,a’) > 0 $$
Deep CFR baseline
The policy network is a multilayer perceptron with hidden layers of size (256,256), while a second network predicts regret-like action scores. The baseline strategy loss is:
$$ L_{\text{strategy}} = \frac{1}{B}\sum_{i=1}^{B} w_i ||\hat p_\theta(I_i)-p_i^\star||_2^2 $$
Soft Regret Matching (SoftRM)
Let $\hat{R}_t(I,a)$ denote the regret-like score predicted by the network. I define a smoothed policy by:
$$ \sigma_{t+1}^{\text{soft}}(a|I) = \frac{\exp(\lambda \hat{R}t(I,a))}{\sum{a’ \in A(I)} \exp(\lambda \hat{R}_t(I,a’))} $$
where $\lambda > 0$ is a regularizing parameter. This update can be interpreted as an entropy-regularized policy choice. For a fixed state $I$:
$$ \pi^\star(\cdot|I) = \arg\max_{\pi \in \Delta(A(I))} \sum_{a \in A(I)} \pi(a|I)\hat{R}_t(I,a) + \frac{1}{\lambda} H(\pi(\cdot|I)) $$
where $H(\pi) = - \sum \pi(a|I)\log \pi(a|I)$ is the Shannon entropy.
Entropy-regularized policy-loss variant
I also tested regularizing the strategy-network training loss directly:
$$ L_{\text{total}} = L_{\text{strategy}} - \alpha H(\hat p) $$
Experiments / Results / Discussion
Experimental setup and metrics
The primary metric is EV against an MCCFR opponent:
$$ \text{EV}(m,k) = \frac{1}{N}\sum_{i=1}^{N} r_i $$
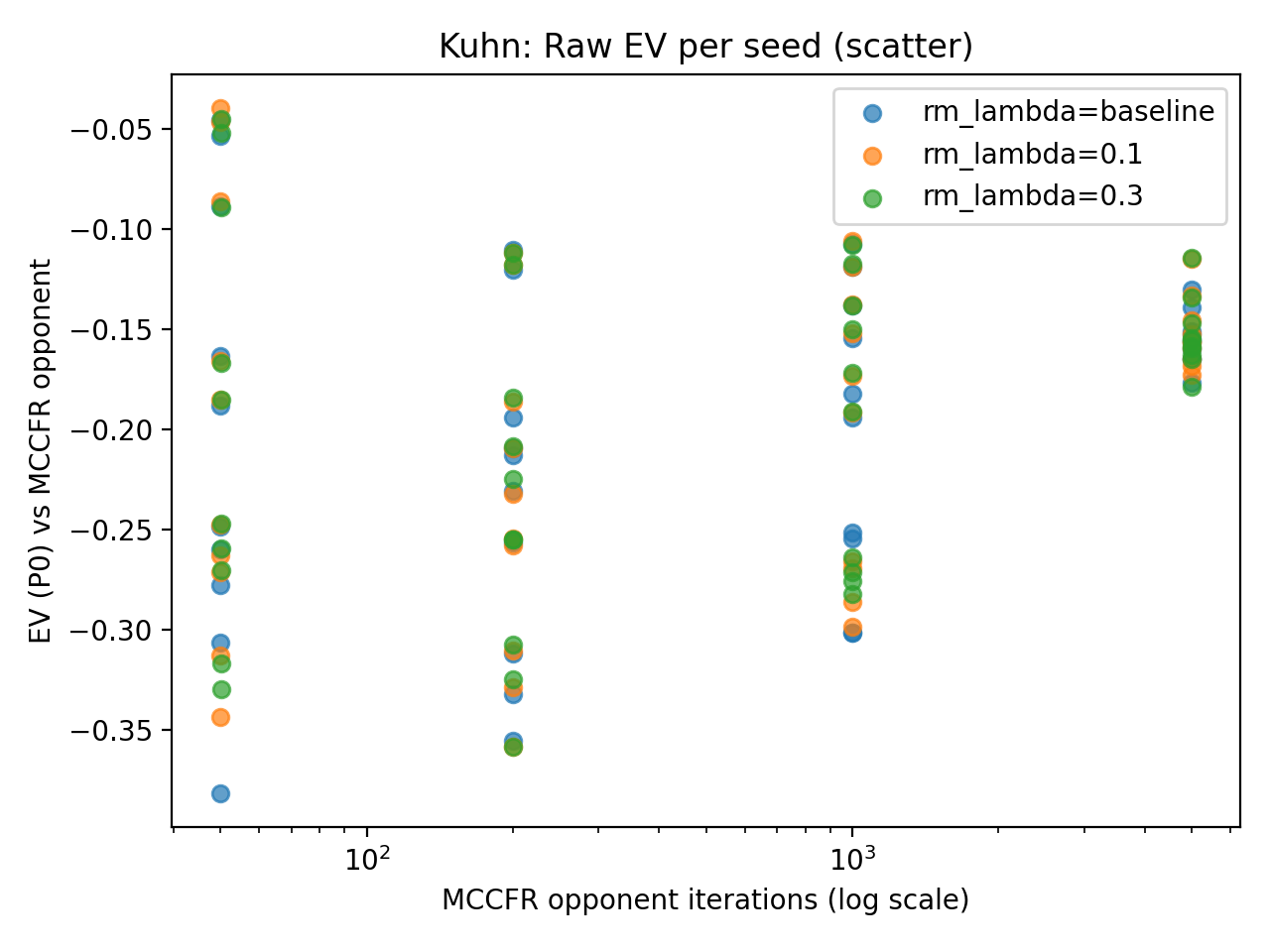
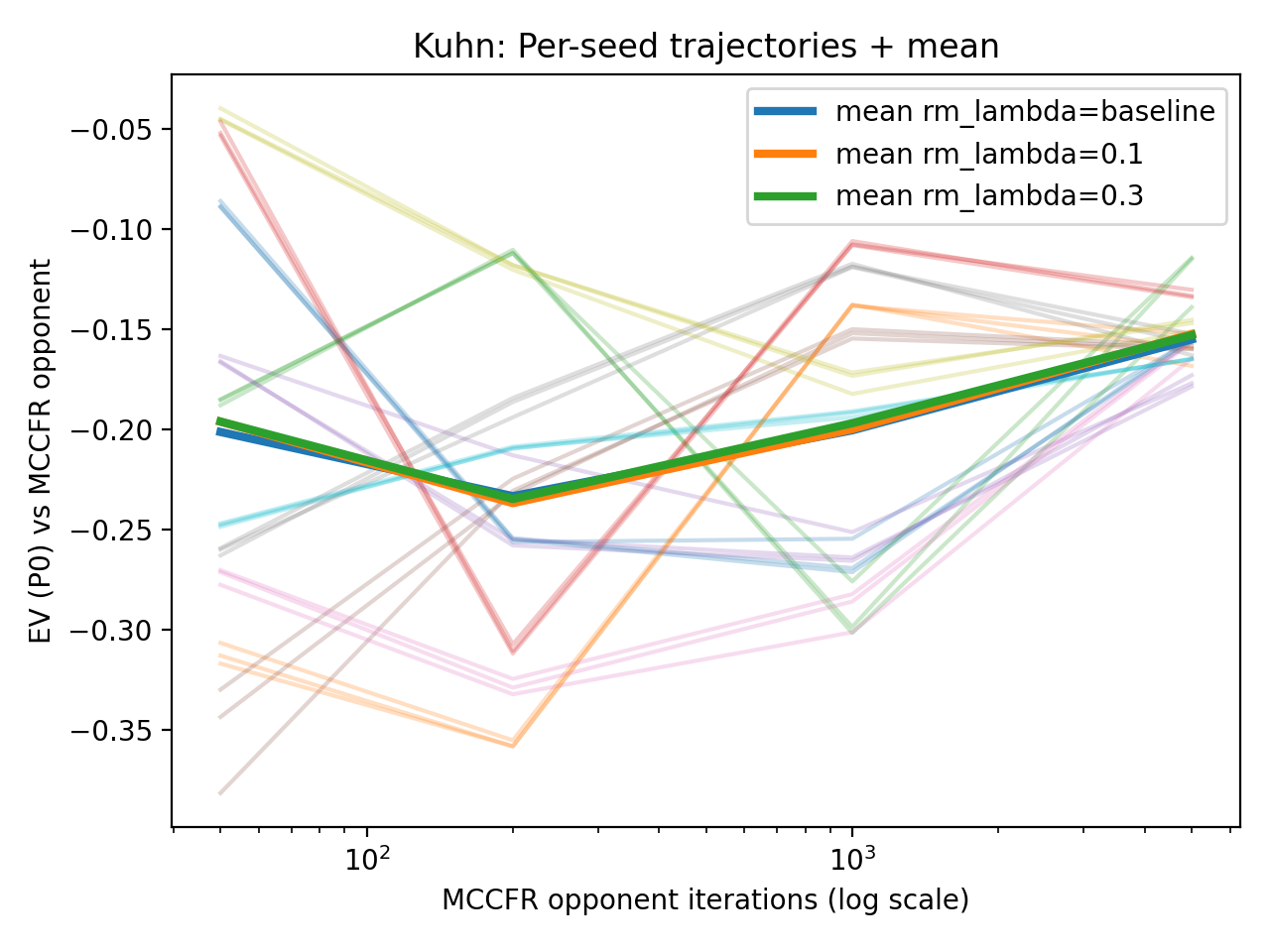
Top: Mean EV and paired differences. Bottom: Raw seed data demonstrates that seed-specific variation dominates the algorithmic effects.
Main Results
Against the 5000-iteration MCCFR opponent, baseline Deep CFR achieves mean EV -0.1551, compared with -0.1525 for SoftRM ($\lambda=0.1$). Variance across seeds was substantial, but within a given seed, the three methods moved together, suggesting the smoothing parameter had less impact than the training seed.
Policy Entropy Check
Mean policy entropy changed only slightly:
- Baseline: 0.6906
- SoftRM ($\lambda=0.1$): 0.6911
- SoftRM ($\lambda=0.3$): 0.6911
Conclusion
SoftRM did not significantly improve performance against MCCFR opponents in Kuhn Poker. The tiny entropy shift suggests the smoothing was too weak or the state space too small to allow for meaningful strategy divergence. Future work should scale this to Leduc Hold’em to see if the complexity allows the regularizer more “room” to work. Next step is to move to larger games where there is greater room for entropy to develop differences in policy, and to test other models, such as an ensemble reinforcement learning model.